ジャンガおじさん統計学を学ぶ。その2
こんにちは、ジャンガおじさんです。
前回に引き続き統計学を学んでいきました。
まず初めにデータの性質の捉え方について学んでいきます。
データの性質を学ぶ上で下記の2つが重要になってきます。
1.データの可視化からデータを理解すること
ーヒストグラムの理解
2.データの性質をどう捉えるか
ー基本統計量(平均・中央値・分散・標準偏差 等)の理解
※基本統計量なんて言葉は別に重要じゃありませんよー
統計学の初めの一歩として、
・データを正しく集計、報告できる
・正しい集計によりデータに基づいた意思決定&意思疎通の精度を上げたり、新たな仮説を行えるようにしていきます。
ここでデータ集計に関する簡単な例をだします。
あなたはあるIT企業のWebマーケティングマネージャーです。
先日行われた新しくローンチしたサービスに関する満足度アンケートの結果を部下より
受け取りました。
部下のアンケート結果の報告は下記のようなものでした。
| N=6 | 使用意向平均点数 |
| サービスA | 3点 |
| サービスB | 3点 |
1点:まったく使用したくない
2点:あまり使用したくない
3点:どちらともいえない
4点:まあ使用したい
5点:使用したい
部下:自社のサービスAとサービスBの満足度の平均点は同率であり、
このアンケートからどちらのサービスのプロジェクトを進めるべきかを決められないと考えます。
→あなたならどう解釈しますか?
(ちょっと極端な数字ですが例なので、、)
ちょっと立ち止まって考えてみてください。
実はこんなデータでした!
| 満足度 | ||
| 顧客ID | サービスA | サービスB |
| 1 | 3 | 1 |
| 2 | 3 | 5 |
| 3 | 3 | 1 |
| 4 | 3 | 5 |
| 5 | 3 | 1 |
| 6 | 3 | 5 |
よく見てましょう。
確かに平均だけを見ると、
サービスA;3点
サービスB;3点
→これを同程度の使用意向であると評価して問題ないのでしょうか
それはアカンのです!!!!!!!
今からとても大切なことを書きます。
是非覚えておいてください。
集計=情報量の削減
※集計とは平均(基本統計量)などを用いること
この情報量の削減をしているという意識がめちゃくちゃ大事です!!!!!!!
正しく集計できる=データがもつ特性を理解し、いくつかの数値やグラフで表現できる
データが持つ特性=データの分布
さっそくデータをグラフ化しましょう。

ここで気づいて欲しかったこととしては、
サービスBには使用意向の低い層と高い層に分かれている!!!!!!
このケースで平均を報告して良いのか?→平均を報告すると誤解を生む
報告すべき内容は、
ー商品Bには極端に「ささる」消費者がいる可能性
ー仮説を再度設定し、再調査を行う必要がある
ちょー簡単な例でしたが、イメージはついたでしょうか??

データ分析の最初の1歩はヒストグラムを理解することです。
・サンプルデータの分布を確認する
・分布を確認するためには、ヒストグラムを作る
ヒストグラムの見方としては下記のような視点がありますので注意して確認しましょう!!
・どのような形か(左右対称か?)
・山がいくつあるか?
・外れ値がないか?
・データの「中心」はどのあたりか?
上記の部下の使用意向の例で出てきたように、サンプル平均とは
. 「データの合計をデータ数で割ったもの」で表すことができます、
(普通の平均と変わんないですよね。笑。サンプル平均といいます。)
例ではなんだか平均が悪者であるかのように表現されていましたが、
そんなことはありません!!
物事にはほとんどメリット、デメリットがあるのですよ!!
▼平均のメリット・デメリット
メリット
誰しも理解しやすい
統計的に良い性質がある
デメリット
極端に小さい・大きい数値があると平均を引っ張る(データ量が少ないときは特に危険
この平均のデメリットを払拭するために別の基本統計量が使われる場合があります!
代表的なのが、平均の代わりに中央値が用いられる場合です。
データを順番に並べた時の真ん中の数値のことです。
分かりやすい図例がこれです。
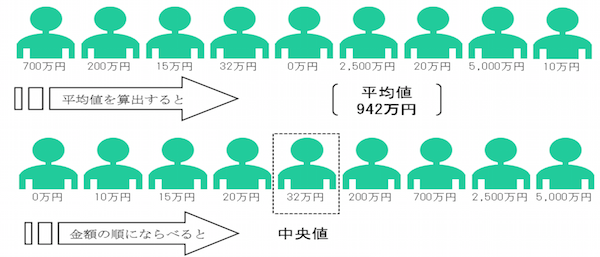
平均値が942万円に対して、中央値が32万円、、、笑
ちょっと極端な例ですがこのような違いが生まれてしまいます。
先ほど書いたように、
集計=情報量の削減
※集計とは平均(基本統計量)などを用いること
この情報量の削減をしているという意識がめちゃくちゃ大事です!!!!!!!
先ほども言いましたが、世の中に存在するものは大半メリット、デメリットがあります。(再掲)
▼中央値のメリット・デメリット
メリット
極端に小さい・大きい数値の影響を受けにくい
デメリット
統計的に良い性質はあまり持ち合わせていない
平均と中央値の使い分けは下記になります。
| 平均 | 中央値 | |
| サンプル数 | 多い | 少ない |
| データの分布 | 左右対称 | 左右対称ではない、外れ値がある |
→実際は分布を見ながら分析者がどちらのデータが分析の際にふさわしいか判断する必要があるのです!!!!!!
ここでようやく、分散と標準偏差についてお話をしていきます。
「分散」と「標準偏差」は2つともデータの散らばり具合を示します
分散を道ぐステップ下記になります。
①偏差を求める
②全変動を求める
③分散を求める
それぞれ具体的に書いていくと下記になります。
1.分散
分散=全変動/データの個数
2.全変動
全変動=偏差の2乗の合計
3.偏差
偏差=データー平均
分散と標準偏差の違いってなんだよ!!と思われる方がいると思いますが、
同じ意味なので気にしなくていいです笑
軽く説明すると分散は非常に使いにくい!!!!!!!
偏差(データー平均)の2乗を合計しているため、平均に足したり引いたりできない。
→標準偏差の必要性
標準偏差=√分散
※分散の2乗を元に戻すだけなので、標準偏差と分散の大小関係は崩れることはありません。
ここでのポイントは
データの散らばりが違う=大事な情報
ということです。
「ジャンガおじさん統計学を学ぶ。その2」のおさらい
ヒストグラム→データの可視化
基本統計量=データの特徴捉え方
ー平均→データの合計をデータ数で割ったもの
ー中央値→データを並べた時の真ん中
ー分散→データの散らばり具合
ー標準偏差→データの散らばり具合
これだけ覚えておけば問題ありません。