地頭力を鍛える(フェルミ推定)
地頭力を鍛える一番良い方法はフェルミ推定であると言われています。
『フェルミ推定(フェルミすいてい、英: Fermi estimate)とは、実際に調査するのが難しいようなとらえどころのない量を、いくつかの手掛かりを元に論理的に推論し、短時間で概算することを指す。オーダーエスティメーションや「封筒裏の計算(英語)」ともいわれる。』
フェルミ推定はコンサルの面接や外資の面接などで良く問われることがあります。
何故、面接で問われると思いますか?
それはフェルミ推定は暗記では対応できないと考えられており、答えのない問に対して仮説を立て論理的に考えることが求められる為、求職者のふるい落としを効率的に行えるからなのです。効率的にとはそれだけ明暗がわかれる問いであり、普段から頭を使っている人と使っていない人の差がとても明確になります。
そんなフェルミ推定ですが、今回は体系立てて少しでもフェルミ推定を理解し、知の世界に足を踏み入れてほしいと考え書いております。
(0)学ぶ前に知っておくと良いこと「ストック問題」と「フロー問題」
ストック、フローとは?
まず、フェルミ推定問題を大きく二分する「ストック」(stock)と「フロー」(flow)という用語について説明します
辞書で「ストック」を調べると「ある一時点に存在する経済諸量の大きさを示す概念」、一方で「フロー」は「経済諸量が一定期間内に変化または生起した大きさを示す概念」という説明が出てきます。
よりかみ砕いて説明するならば、「ストック」とは「あるモノの一時点における存在量」のことであり、一方で「フロー」は「あるモノの一定期間における変化量」のことです。
たとえば、「ピアノ」を例に考えてみましょう 。
○ストックとフローの具体例
「シカゴにおけるピアノの数」と「シカゴにおけるピアノの市場規模(年間)」……果たしてどちらが「ストック」で、どちらが「フロー」でしょう
答えは、「シカゴにおけるピアノの数」が「ストック」であり、「シカゴにおけるピアノの市場規模(年間)」が「フロー」です。
市場規模(年間)は1年間のピアノのシカゴ内総販売額を集計したものですから、「1年間という一定期間で自動車がシカゴで売られた量(金額)」といえますね
たとえていうと、「ストック」は「容器の中の水の量」であり、「フロー」は「一定時間に蛇口から容器へ注がれる(容器から出ていく)水の量」です。後者の「フロー」は、「1分間に10リットル」のように、一定時間あたりの量を表しているという特徴があります。
(1)基本ステップの解説
フェルミ推定は、基本的に次の5つのステップで進めていきます。
①前提確認 ②アプローチ設定 ③モデル化 ④計算実行 ⑤検証
ここでは、一番有名で基本である「シカゴにピアノの調律師は何人いるのか。」という問題を例に、この5つのステップを順に説明していきます。
①前提確認
ここでは「ピアノ」の定義を明確にしていきます。今回で言うと調律できるピアノであり、電子的なピアノは含まれていません。※今回は家庭にあるピアノを算出していきます。
ⅰ.「ピアノ」をどのように定義をするか「定義」
ⅱ.どのような「ピアノ」を数えるのか「範囲の限定」
を明確にしていきます。
②アプローチ設定
ここでは基本的な式を設定します。いきなりシカゴのピアノの調律師の数を導き出すことはできません。
そこで中学校でならった因数分解をしていきます。
シカゴのピアノの調律師の数を出すためには、
ピアノ調律師の数=ピアノ調律需要÷調律師一人当たりの年間調律件数
を導き出すと答えにたどり着きます。
ここで前提となっている認識としては、需要=供給 ということです。
需要というのはピアノの調律師です。「シカゴでいったいどのくらいのピアノの調律需要があるのか?」という数字です。
供給量というのは、まさにピアノ調律師の数です。シカゴにはその地域のピアノ調律需要を満たすに十分な調律師がいるはずだと考えよということです。
③モデル化
ここでは②アプローチ設定で立てた基本式の深堀を行っていきます。
基本式をみていくと、『ピアノ調律需要』『調律師一人当たりの年間調律件数』という変数があります。
この2つの変数をさらに因数分解していくことを③モデル化で行っていきます。
②アプローチ設定と③モデル化の違いは前者は横のアプローチであり、後者は縦のアプローチとなっています。
ピアノ調律需要=シカゴ世帯数×ピアノ保有率×ピアノ調律の頻度
調律師一人当たりの年間調律件数=一日あたり調律件数×年間労働日数
に因数分解をすることができます。
④計算実行
それでは③で求めたモデル式を計算していきます。
ピアノ調律需要=シカゴ世帯数×ピアノ保有率×ピアノ調律の頻度
▼世帯数の推定
シカゴ世帯数はどう求めるかというと、人口÷平均世帯人数です。
シカゴの人口はどうやって求めるの?そんなの知らないよ!と思われるかもしれないですが、ここで大切なことは推定のためにどういう推定式を使うか、という論理の方です。実際は③モデル化までは導き出せればほぼフェルミ推定は完了しています。
ここではざっくり東京の人口が1000万人だからそこまではいかないだろう。でも都市としては世界で10番目ぐらいには入っていそうだ。なので300万人ぐらいと予想しよう!
みたいな感じで最初の方は考えて問題ありません。フェルミ推定を嫌いになるぐらいならそれぐらいの気軽さで考えたほうが良いと思っています。
考え方というのは習慣にしないと確実に身に付きません。ですので、まずはやってみることが大切なのです。
次に平均の世帯数ですが、感覚的に母親、父親、子供が平均的な世帯であると仮定し、
3人とします。結果としてシカゴ世帯数は300万人÷3人=100万世帯と導ぎだせます。
▼ピアノ保有率の推定
シカゴ世帯数が100万世帯としたときに、ピアノを保有する可能性があるとする裕福なファミリー層は50%といると仮定し、そして実際に保有する世帯を10%で計算していきます。
100万世帯×50%×10%=5万台
シカゴの家庭で保有されているピアノの数は5万台という結論が出ました。
そしたピアノ調律頻度はざっくり年一回程度だろうと仮定します。
そうすると、
ピアノ調律需要
=シカゴ世帯数×ピアノ保有率×ピアノ調律の頻度
=100万世帯×5%×1回/年間
=5万件/年間
と導くことができます。
調律師一人当たりの年間調律件数=一日あたり調律件数×年間労働日数
▼一日あたり調律件数
こちらはピアノの調律は各家庭を回るわけですから、移動時間等のコストが入ります。
そう考えると、大体午前1回、午後2回程度の調律が想定できます。
ですので一日あたりの調律件数を3件と仮定します。
▼年間労働日数
こちらざっくり土日を休みにして大体200日ぐらいだろうと仮定します。
そうすると、
調律師一人当たりの年間調律件数
=一日あたり調律件数×年間労働日数
=3件×200日
=600件
と求めることができます。
そして最後に上記で求めた変数を代入すると、
ピアノ調律師の数=ピアノ調律需要÷調律師一人当たりの年間調律件数
=5万件/年÷600件/年
=約83人
と導くことができました。
ここで気を付けてほしいことは「単位を揃えるということ」です。
今回の問題で言えば「年間」で統一をしています。
⑤検証
検証の方法として一番簡単なのが、
シカゴの人口で割ってみるということです。
300万人÷83人=36,000人
約36,000人に1人の割合でピアノ調律師が存在することになります。
30人に1人とかの割合で出してしまうと公務員ぐらいの数になってしまうので、
明らかにどこかの推論が間違っている可能性があります。
ですので今回の推論をおそらくこのぐらいの数であろうということが分かります。
すぐに読めるのでお勧めです↓
ジャンガおじさん統計学を学ぶ。その5(ビジネス応用編)
こんにちは、ジャンガおじさんです。
前回はかなりザクっと確率分布についてまとめていきましたので、
今回記事の中で出てきた分布について具体的に掘り下げていきます。
下記のケースを読んでみてください。
あなたWEBサービスの責任者です。
・あなたが働いている企業では3か月前に検索サービスをリリースしました。
・検索サービスは広告モデルで広告収入を得て成り立っています。
バックオフィスのエンジニアが駆け寄ってきてこんなことを言ってきました。
「新しいUIはサーバーへの負荷が高いので1分間に同時に980人検索サイトに訪れるとかなり読み込みが遅くなり重たくなってしまいます。1000人を超えるとアウトです。。。。」
下のデータは12月5日の1分間ごとの来訪者数です。
この時の検索サービスの1分間の平均来訪者数を940人だとします。
| 時間 | 分 | 来訪者 |
| 0 | 0 | 776 |
| 0 | 1 | 886 |
| 0 | 2 | 989 |
| 0 | 3 | 835 |
| 0 | 4 | 760 |
| 0 | 5 | 875 |
| 0 | 6 | 769 |
| 0 | 7 | 865 |
| 0 | 8 | 962 |
| 0 | 9 | 827 |
| 0 | 10 | 813 |
| 0 | 11 | 916 |
| 0 | 12 | 944 |
| 0 | 13 | 967 |
| 0 | 14 | 878 |
| 0 | 15 | 885 |
さて、1001人以上の人が同時に検索サービスに来訪する確率はどの程度でしょうか???
ある程度イメージはできているでしょうか。
統計学を用いると将来をある程度予測することができるので、
不確実性が高いビジネス世界においてとても重宝される学問であり、
ビジネスとはとても相性が良いのです。
では、具体的に考えていきましょう。
まずやることは
1、まずサンプルデータの形を確認する
ヒストグラムを作ると、1001人以上の同時にサイトに訪れてはいないことがわかります。
では、1001人以上の同時来訪はない=確率0%なのでしょうか??
いいえ、違うのです。
サンプルデータから直接確率を算出するのは問題があるのです。
・観測していないものは確率が0になってしまう。
・もし観測したデータがあってもサンプル数が少なければ、極端な確率が出てしまう。
→
「統計学」を使うことで
観測していなくても(近似的に)確率を
出すことができます。
あなたが知りたいのは未来永劫の確率です。
サンプルから母集団を推測するには?
・サンプルの世界≠母集団の世界
・サンプルから母集団を推測するにはどうしたらよいか?
~母集団を推測するからくり~
統計学には母集団の「分布の型」が用意されており、母集団はその分布に従っていると仮定するとします。
~母集団はXX分布に従うと仮定しよう!~
・分布の型は「パラメータ」で分布の形が変わります。
・サンプルから母集団に仮定した「分布の型」のパラメータを推定=形を推測する。
「パラメーターを推定すると分布の形が決まる。」
これはめちゃくちゃ大切ですので覚えておいてください。
復習をしていきましょう!
★サンプルから推定するのはパラメーター
・「分布の型」は理論分布と呼ばれる
・理論分布の形はパラメーターと呼ばれる
いくつかの数値できめられる
→
ここでのゴール
・母集団に理論分布を仮定し、
・サンプルから理論分布のパラメーター全てを推測すること
・これができれば、母集団の分布が推測できる
先ほどのケースに当てはめてみましょう!
一分間の同時来訪者数を表現する理論分布はポアソン分布で推測することができるのです。
ポアソン分布について思い出してみましょう。
ポアソン分布とは
・一定期間/空間内で
・あるイベントが起こる回数
を表現するための理論分布=ポアソン分布
▼過去記事
ポアソン分布が当てはまる具体例は下記の通りです。
・ある交差点で1時間に起こる事故の件数
・1ページの文章で誤字がある個数
・1時間に来店する客の数
ポアソン分布は
・一定期間(もしくは一定空間)で
・ある事象が平均??回発生する
と表現できる分布です。
平均??回=これがポアソン分布のパラメーターになります。
パラメーターを変化させると分布の形が変わるというの
下記のグラフをみると一目瞭然です。

下記がポアソン分布の確率質量変数です。(再訂)

λ(ラムダ)というのは平均を表しています。
ポアソン分布で言うパラメーターとは平均のことであり、
つまり平均が分かれば分布の形を特定することができるのです。
では平均はどこから持ってくればよいのでしょうか?
それは、、、
サンプルからパラメーターを推定できるのです!
母集団がポアソン分布だと仮定すると、
サンプルの平均=母集団の平均の推定値
として、おかしくないことが理論的にわかっています!
今回の例で言えば、
サンプルの平均は940人だった!
→
母集団の平均もだいたい940人になる
ということになります。
よって、観測していないデータの確率を計算できるのです。
下記がポアソン分布の確率質量変数です。(再訂)
そして具体的に値を入れていきます。
| イベント数(=k) | 0人から1000人までが起動するので | 1000 |
| 平均(=λ) | 検索サイトを1分間に訪れる平均人数 | 940 |
エクセルで解き方を考えてみましょう。
今回の場合は、
1分間で1001回以上の来訪が発生する確率ですので、
1- (1分間で1000回以下来訪する確率)
になります。
ポアソン分布のエクセル関数は、
POISSON.DIST(イベント数,平均,関数形式)
ですので、エクセルの式はこうなります。
=1-POISSON.DIST(1000,940,TRUE)
=2.51%
よって、1001人以上の人が同時に検索サービスに来訪する確率は2.51%
この2.51%を許容するのか、しないのかはビジネスジャッジになります。
ただ、サーバーおちるのかなーおちないのかなーでも危なそうだようなー
みたいな感覚的に仕事を行うよりも、2.51%という数字を用いて議論するのとでは
全然違います。より経営判断がしやすくなり、データドリブンで仕事ができるようになるのです。
博多行ったら絶対行ってほしい店
どうも、ジャンガおじさんです。
昔仕事の関係でしばらく博多に滞在していて、今回は博多に行ったら必ず行ってほしいお店をご紹介いたします。
(個人的に博多ラーメンは外します。昔食べ過ぎて今では豚骨の匂いを嗅いだだけで気持ち悪くなってしまいますので。)
まず、最初におススメするのが『水たき 長野』。

福岡といえば水炊きなんすよね。福岡行くまでは全然知らなくて、行って現地の人に教えてもらいました。めちゃくちゃ人気なので予約1か月ぐらい普通にかかっちゃいます。残念なところとしてはクレジットカードが使えないんですよね。さっさっと導入してほしいです。
次におススメするのが『はじめの一歩』

ここ来たら、黙ってゴマサバ、ゴマカンパチを喰うべし。
ここまでのクオリティのゴマサバはなかなか東京じゃ味わえないです。
海鮮系なら一番おススメのお店です。
そして、個人的に一番おススメするのがこちらです。
『博多とりかわ大臣』

個人的に一番好きです。
もちろん一番おススメなのがとりかわです。
あの串に刺さったカリカリのとりかわを食べたときは衝撃を受けました。
もつ鍋に関しても美味しいお店たくさんありますが、
ぶっちゃけ東京にも同じような店はたくさんあります。(六本木とか)
水炊きなら『長野』
ゴマサバなら『はじめの一歩』
とりかわなら『とりかわ大臣』(とりかわ粋恭のとりかわもうまいです。)
是非、一度足を運んでみてください。
ジャンガおじさん統計学を学ぶ。その4(確率分布編)
「世の中のデータはどんな分布になるのかあらかた決まっている」
前回、確率分布とはということでまとめていきましたが、
今回は具体的に代表的な3つの確率分布についてまとめていきます。
3つの代表的な確率分布はこちらになります。
②二項分布
コイン投げetc..
「裏表」、「あるない」ことを表す分布
③ポアソン分布
交通事故の確率etc...
めったに起きないことを表す分布
ではさっそく、
正規分布から学んでいきましょう。
①正規分布
ーランダムな誤差を表す分布になります。
正規分布は英語でNormal distributionと言うことからも分かるように『この世でもっとも一般的な分布』であり、「誤差の大きさの出現確率」をはじめ、さまざまな社会現象や自然現象で当てはまる確率分布です。
正規分布とは、平均を μ ・分散を σ2 とした場合に以下の確率密度関数で表される確率分布を指し、N(μ, σ2)と表記されます。

また、ある確率変数X の確率分布が正規分布N(μ, σ2)であるとき「確率変数 X はN(μ, σ2)に従う」と言い、『X ~ N(μ, σ2)』と表記されます。

ビジネスで正規分布が当てはまるケース
・ある工場で製造される部品の寸法の誤差
・証券の値段の不確実性
世の中の社会現象や自然現象の中には、その確率変数が正規分布に従うとみなせるものが多く存在するため、その平均と標準偏差が分かれば、多くの現象について「どういった事がどれくらいの確率で発生するのか」を計算できるようになるんです。
そして次に学ぶのが二項分布
②二項分布とは、
ー結果が2つの試行を何回も繰り返すことによって起こる分布
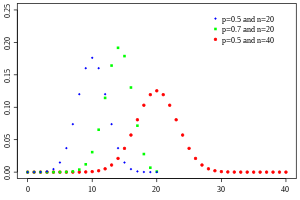
ビジネスにおいて二項分布が当てはまるケース
・N回のページビューのうち、確率pで広告がクリックされる回数
(クリックされるか、されないか)
・N人のユーザーのうち、確率pで解約する人数
(解約するか、されないか)
・N人の社員のうち、確率pで退職する人数
(退職するか、しないか)
少し考えてみればビジネスの世界でもどんどん応用できるようになります。
こんな具体例どんな参考書にも載っていないと思います。
下記が二項分布の確率質量関数の式となる。

※エクセルで簡単に計算できる

n回の試行を行い、
k回成功するとして、
(1回の試行における成功確率はp)
nCk はn回の試行で、k回成功する仕方を表します。
次はあまり聞いたことがないかもしれませんが
なかなか使える分布であるポアソン分布についてまとめていきます。
ポアソン分布
ーある一定時間や一定空間内でイベントが発生する回数を表現
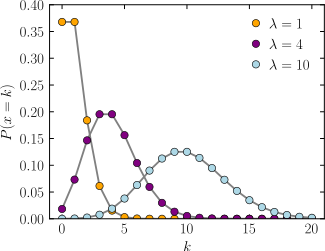
ビジネスでポアソン分布が当てはまるケース
・一カ月で平均n回コンバージョンする広告を使って得る今月のコンバージョン数
・一日に平均n個不良品が作られる工場で、今日作られる不良品の個数
▼ポアソン分布の確率質量関数
Kは一定期間内にイベントが起こる回数、
分布の形はパラメータλに依存します。
※ポアソン分布はPOISSON関数で計算できる

今日はここまで次回は具体的なケースをみていきます。
ジャンガおじさん統計学を学ぶ。その3(確率分布編)
こんにちは、ジャンガおじさんです。
前回は平均、標準偏差など基礎中の基礎についてまとめていきました。
今回はいよいよ統計学っぽいことを学んでいきます。
今回学ぶことは『確率分布』についてです。
聞いたことはありますでしょうか。
世の中で一番有名な確率分布は正規分布であると思うのですが、
確率分布は正規分布だけではないのです。
今回は確率分布についてしっかり学んでいきましょう。
学ぶことは大きく分けて2つです。
▼学ぶこと
1.サンプルの理解から母集団を理解すること
=「確率分布」について学びます
・3つの代表的な確率分布
①二項分布
②ポアソン分布
③正規分布
→「データがどの分布に従うか」ということがデータ分析の方向性を決める要素の1つです。(これから学びますので、焦らずに)
2.得られたデータをどのように分析に利用していくか
=「中心極限定理」について学びます。
ではさっそく
1.サンプルの理解から母集団を理解すること
について学んでいきます。
まずは確率分布について説明をします。
・確率分布とは
ー確率変数が出る値とそれに対応する確率の値を現した分布です
例)サイコロを1回投げた時の確率分布
確率変数?と思われた方がいると思いますが、
・確率変数とは
ー「そのような値になるか」が確率的に決まる変数
あまりイメージがつかないと思いますので、
具体的に説明していきます。
▼具体例
~コインを10回投げて、確率分布を学ぼう~
・コインを10回投げた時の確率を出せますか?
ー10回すべて表が出る確率は?
ー5回表が出る確率は?
ー10回すべて表が出る確率を考えていきましょう!
コイン投げから確率分布を学んでいきます。
・コインを10回投げます
ー10回全てで表が出る確率は?
(1/2)^10=0.001=0.1%
これは
表表表表表表表表表表
の1通りである
これは何となく中学校の知識があれば理解できると思います。
それではこちらの問いは解けますか??
ー5回表5回裏が出る確率は?
表になるのが1/2、裏になるのが1/2なので同様に、
(1/2)^10=0.001=0.1%
なのでは?
違いますね!!!笑
5回表が出る確率は?
5回表、5回裏になるのは何通りあるのか?
→いっぱいある!!!
具体的に書いてみるとわかります。
表表表表表裏裏裏裏裏 →1通り
表表裏裏裏裏裏表表表 →1通り
裏裏裏裏裏表表表表表 →1通り
とかとか、いっぱい可能性はあるんです!
それをどうやって計算すればいいかわかりますか???
(高校生の頃習ったはずです。。)
10C5で計算できる!!!!(Cはコンビネーションです)
ここで言う10C5の意味というのは、
10=10回中
5=5回という表(裏)になるという意味
10C5×(1/2)^5×(1/2)^5
=0.246=24.6%
同じ要領で
0回表が出る確率:0.1%
1回表が出る確率:1.0%
2回表が出る確率:4.3%
3回表が出る確率:11.7%
4回表が出る確率:20.5%
・・・・
と確率を出していきます。その時の、
N回=確率変数
N%=確率
というんです!!
グラフにしてみると、

横軸は「サイコロが表になった回数」
横軸は「確率」になるのです。
よく見たことあるグラフではないでしょうか?
▼離散的確率と連続的確率
・今までは結果の数が有限だったんですが、、、
=>離散的確率
(サイコロの目だと1,2,3,4,5,6)
しかし、身長のような結果の数が無限ととれるような場合、
(基本的にスパっと決まらないはずです。170.1111...cmとか)
どのように表すのかというと「連続的確率」で表すのです。
そして連続的確率をグラフで表すために、
これからしっかり学んでいきます。
その前にに離散的確率(サイコロとか)は
確率質量関数(PMF)と呼ばれる関数で表すことができます。
確率質量関数とは、
確率的変数のそれぞれの値の確率をグラフで表したもの
ー離散的確率を見るときに使うのです。
例えば、
・サイコロの目が1になる確率
・コインを投げて表になる確率
...etc
次に連続的確率(株価とか)についてグラフで表すために、
確率密度関数(PDF)が用いられます。
確率密度関数で重要なことは下記になります。
・確率変数のそれぞれの値の確率をグラフで表したもの
・面積は必ず1
・面積を求めることで確率が求まる
・連続的確率を見るときに使う
例えば、
身長がXXcm以上になる確率
徒競走のタイムが00秒以内になる確率
etc..
確率質量関数と確率密度関数についてグラフで記載したものが下記の図1になります。
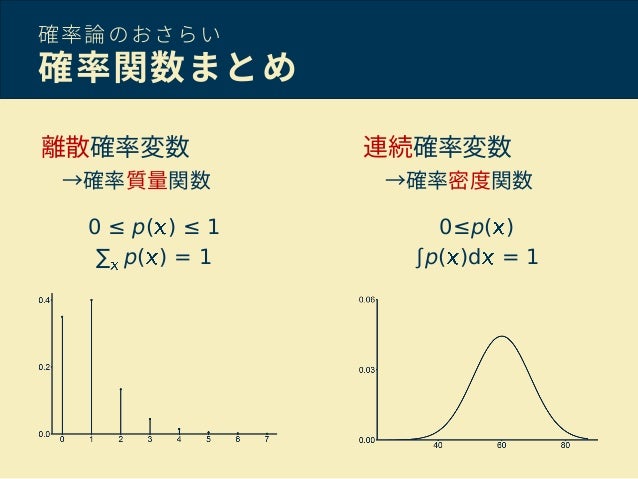
図1
あと知っておくといいのが、
累積分布関数(CDF)という関数があります。
累積分布関数とは
・確率密度関数で得られた確率を順々に足していく
・0から1の右上がりになっているもの
となる関数を指します。
確率分布で大切なことは下記のとおりです。
確率分布とは
1、イベント発生回数や数値と、それらが得られる理論上の確率の関係を表現した関数・グラフ
2、全ての可能性を足したら、必ず確率は1になる
3、確率分布の形を規定する変数を「パラメーター」という
4、確率分布には名前と、どんな状況やデータのとり方をしたときに使うかが概ねきまっている
ビジネスの世界で用いるとなると、4についてはより重要になってきます。
知識や経験が増えるとともに状況によって用いるべき分布の形が分かるからです。
では次回、代表的な3つの分布についてまとめていきます。
ジャンガおじさん統計学を学ぶ。その2
こんにちは、ジャンガおじさんです。
前回に引き続き統計学を学んでいきました。
まず初めにデータの性質の捉え方について学んでいきます。
データの性質を学ぶ上で下記の2つが重要になってきます。
1.データの可視化からデータを理解すること
ーヒストグラムの理解
2.データの性質をどう捉えるか
ー基本統計量(平均・中央値・分散・標準偏差 等)の理解
※基本統計量なんて言葉は別に重要じゃありませんよー
統計学の初めの一歩として、
・データを正しく集計、報告できる
・正しい集計によりデータに基づいた意思決定&意思疎通の精度を上げたり、新たな仮説を行えるようにしていきます。
ここでデータ集計に関する簡単な例をだします。
あなたはあるIT企業のWebマーケティングマネージャーです。
先日行われた新しくローンチしたサービスに関する満足度アンケートの結果を部下より
受け取りました。
部下のアンケート結果の報告は下記のようなものでした。
| N=6 | 使用意向平均点数 |
| サービスA | 3点 |
| サービスB | 3点 |
1点:まったく使用したくない
2点:あまり使用したくない
3点:どちらともいえない
4点:まあ使用したい
5点:使用したい
部下:自社のサービスAとサービスBの満足度の平均点は同率であり、
このアンケートからどちらのサービスのプロジェクトを進めるべきかを決められないと考えます。
→あなたならどう解釈しますか?
(ちょっと極端な数字ですが例なので、、)
ちょっと立ち止まって考えてみてください。
実はこんなデータでした!
| 満足度 | ||
| 顧客ID | サービスA | サービスB |
| 1 | 3 | 1 |
| 2 | 3 | 5 |
| 3 | 3 | 1 |
| 4 | 3 | 5 |
| 5 | 3 | 1 |
| 6 | 3 | 5 |
よく見てましょう。
確かに平均だけを見ると、
サービスA;3点
サービスB;3点
→これを同程度の使用意向であると評価して問題ないのでしょうか
それはアカンのです!!!!!!!
今からとても大切なことを書きます。
是非覚えておいてください。
集計=情報量の削減
※集計とは平均(基本統計量)などを用いること
この情報量の削減をしているという意識がめちゃくちゃ大事です!!!!!!!
正しく集計できる=データがもつ特性を理解し、いくつかの数値やグラフで表現できる
データが持つ特性=データの分布
さっそくデータをグラフ化しましょう。

ここで気づいて欲しかったこととしては、
サービスBには使用意向の低い層と高い層に分かれている!!!!!!
このケースで平均を報告して良いのか?→平均を報告すると誤解を生む
報告すべき内容は、
ー商品Bには極端に「ささる」消費者がいる可能性
ー仮説を再度設定し、再調査を行う必要がある
ちょー簡単な例でしたが、イメージはついたでしょうか??

データ分析の最初の1歩はヒストグラムを理解することです。
・サンプルデータの分布を確認する
・分布を確認するためには、ヒストグラムを作る
ヒストグラムの見方としては下記のような視点がありますので注意して確認しましょう!!
・どのような形か(左右対称か?)
・山がいくつあるか?
・外れ値がないか?
・データの「中心」はどのあたりか?
上記の部下の使用意向の例で出てきたように、サンプル平均とは
. 「データの合計をデータ数で割ったもの」で表すことができます、
(普通の平均と変わんないですよね。笑。サンプル平均といいます。)
例ではなんだか平均が悪者であるかのように表現されていましたが、
そんなことはありません!!
物事にはほとんどメリット、デメリットがあるのですよ!!
▼平均のメリット・デメリット
メリット
誰しも理解しやすい
統計的に良い性質がある
デメリット
極端に小さい・大きい数値があると平均を引っ張る(データ量が少ないときは特に危険
この平均のデメリットを払拭するために別の基本統計量が使われる場合があります!
代表的なのが、平均の代わりに中央値が用いられる場合です。
データを順番に並べた時の真ん中の数値のことです。
分かりやすい図例がこれです。
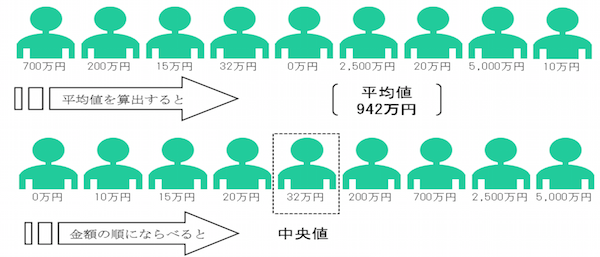
平均値が942万円に対して、中央値が32万円、、、笑
ちょっと極端な例ですがこのような違いが生まれてしまいます。
先ほど書いたように、
集計=情報量の削減
※集計とは平均(基本統計量)などを用いること
この情報量の削減をしているという意識がめちゃくちゃ大事です!!!!!!!
先ほども言いましたが、世の中に存在するものは大半メリット、デメリットがあります。(再掲)
▼中央値のメリット・デメリット
メリット
極端に小さい・大きい数値の影響を受けにくい
デメリット
統計的に良い性質はあまり持ち合わせていない
平均と中央値の使い分けは下記になります。
| 平均 | 中央値 | |
| サンプル数 | 多い | 少ない |
| データの分布 | 左右対称 | 左右対称ではない、外れ値がある |
→実際は分布を見ながら分析者がどちらのデータが分析の際にふさわしいか判断する必要があるのです!!!!!!
ここでようやく、分散と標準偏差についてお話をしていきます。
「分散」と「標準偏差」は2つともデータの散らばり具合を示します
分散を道ぐステップ下記になります。
①偏差を求める
②全変動を求める
③分散を求める
それぞれ具体的に書いていくと下記になります。
1.分散
分散=全変動/データの個数
2.全変動
全変動=偏差の2乗の合計
3.偏差
偏差=データー平均
分散と標準偏差の違いってなんだよ!!と思われる方がいると思いますが、
同じ意味なので気にしなくていいです笑
軽く説明すると分散は非常に使いにくい!!!!!!!
偏差(データー平均)の2乗を合計しているため、平均に足したり引いたりできない。
→標準偏差の必要性
標準偏差=√分散
※分散の2乗を元に戻すだけなので、標準偏差と分散の大小関係は崩れることはありません。
ここでのポイントは
データの散らばりが違う=大事な情報
ということです。
「ジャンガおじさん統計学を学ぶ。その2」のおさらい
ヒストグラム→データの可視化
基本統計量=データの特徴捉え方
ー平均→データの合計をデータ数で割ったもの
ー中央値→データを並べた時の真ん中
ー分散→データの散らばり具合
ー標準偏差→データの散らばり具合
これだけ覚えておけば問題ありません。